Had a look through the forum. Are you looking at introducing vulnerability logging into assets. I thought I had seen this but i may have just dreamt about it.
If not it would be great to be able to log vulnerabilities against the assets in a table associated with the asset. If we can have this as an open closed status we can track open vulnerabilities before the application would upgraded and track vulnerabilities over time.
Yes Nessus scans would be good however, we use OpenVas as part of our AlienVualt Security Appliance so it would need to be flexible enough maybe a csv import or something. But it would be good to be able to add vulnerabilities in manually. For example if we have a Pen Test carried out on an application or our network infrastructure this is not readily available to be automatically imported so I would need to ability to add vulnerabilities manually. The purpose of this is that when a project comes along to to improve the asset we can then see all of the vulnerabilities that are associated with the asset. Ideally we can link these vulnerabilities then to the risks with the asset
Record vulnerabilities manually or with CSV (we have some logic for CSV inputs)
Once we upload that , how we make it useful? just thinking (openly)
We set notifications for deadlines
We set filters
I would like to be able to import vulns with CSV or APIs and “compare” if what i found on day 1 is the same as i found in day 6 … in that way i know if somethign got fixed.
This would belong to “Security Operations” module, my guess.
Can you share how a CSV import for OpenVas looks like?
globant.com (NYSE:GLB) has pretty much confirmed me they will sponsor this features, the three features will be:
describe what versions you are running on software, libraries, etc and review daily for mitre and/or nvd if any of those is subject to a vulnerability. if yes, document an issue, follow up, notifications, etc.
monitor ssl certificates … not sure you but i mess up renewals every time i can
upload a scan (for a target such a server, cluster, network, etc) done with some vendor (nessus and acunetix first) , tag those that not important, those that are important and need follow up … then being able to upload a second scan and show differences.
As i understand this will start being developed / designed in mid april and i foresee 3-4 months of development.
A bit of work done on this today, things moved on quite a lot since my pentester days (like a decade ago) and so i had to spend some hours catching up on how public vulnerabilities are stored (metadata in particular).
NVD (the “new” CVE) is likely to be the source for published software vulnerabilities you will be able to download and check against your software definitions to know:
Is my software vulnerable to something?
A bit of what i learned today:
CVE are pulled by NVD (nvd.nist.gov) every day or minute i’m not sure.
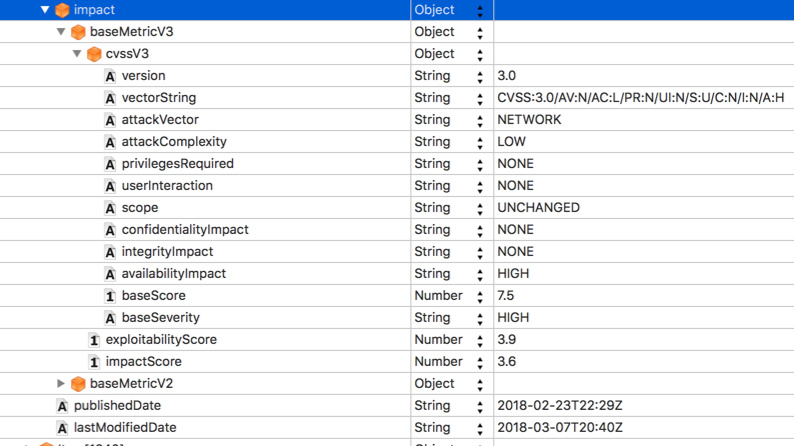
NVD uses a far more elaborated JSON to store the CVE metadata and include many more things, the most relevant to me are:
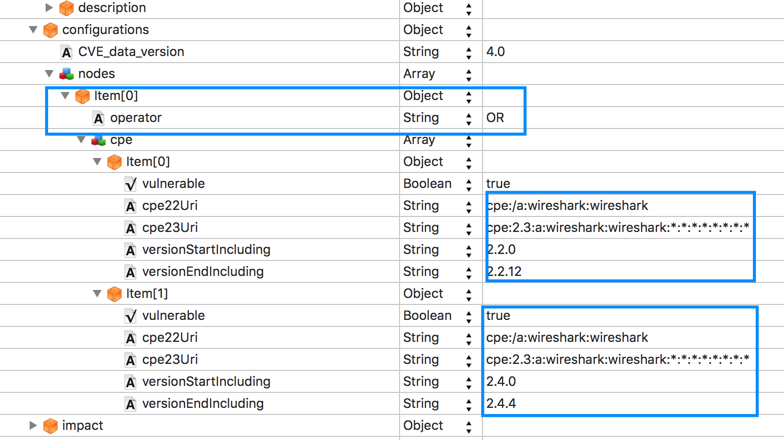
CPEs (this is the vendor, product, version (and i think language) affected. Is far more elaborated than saying “Cisco” with the purpose of being able to structure their data in a way you can make queries to the version level)
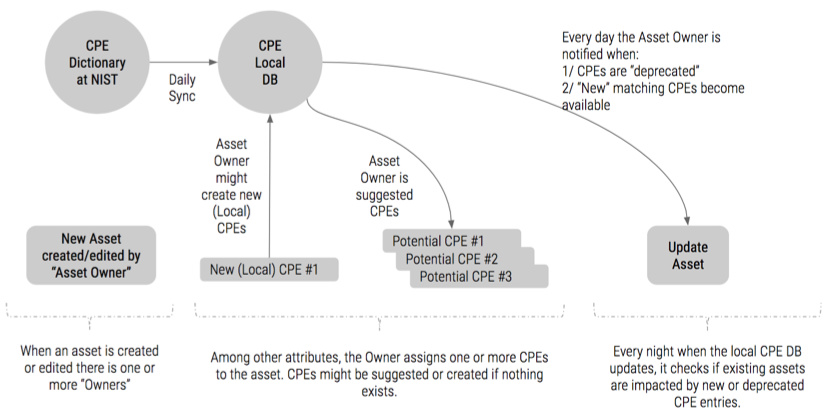
1- You define your software (Asset Management/Etc) and their relationship. You’ll assign an existing CPE (from the NVD database pulled every day) or create a new one on eramba (which will be “local” to you)
2- eramba will pull the NVD JSON files, no clue at this point how to store them as they are very complex metadata models that wont fit in a DB straight away.
3- Using the CPE magic comparisons will be done in between what you defined and what was pulled
4- Potential matches shown for you to manage and so (that piece will be in a DB for sure)
At this point the volume and model of data is what concerns me most. Also i still dont fully understand how CPE works but i guess a bit more reading will provide clues.
If any of you had any contact with this stuff at this level of detail, much appreciated
An attribute-value pair is a tuple a=v in which a (the attribute) is an alphanumeric label (used to
represent a property or state of some entity), and v (the value) is the value assigned to the attribute.
wfn:[a1=v1, a2=v2, …, an=vn]
Only the following attributes SHALL be permitted in a WFN attribute-value pair:
part
vendor
product
version
update
edition
language
sw_edition
target_sw
target_hw
other
Each permitted attribute MAY be used at most once in a WFN. If an attribute is not used in a
WFN, it is said to be unspecified.
Attributes of WFNs SHALL be assigned one of the following values:
A logical value (ANY or NA always in upper case)
A character string satisfying (no case sensitive)
There are a few rules (no spacing, capital letters, etc described on 5.3.2)
Some do not have a CPE entry at all (NVD is in theory in charge of completing those missing CPEs - good example is CVE-2016-9748)
Wrong CPE is assigned to some CVEs
CPEs deprecation trigger when an entity has a wrong name, CPEs get updated but not CVEs which remain pointing to the wrong CPE URI entry. CVE feeds (as of February 14th, 2017) contain 105,591 CPE entries that do not exist in the CPE dictionary
The process of assigning CPEs to assets seems a bit like this for now:
Comparisons in between CPEs will be needed, for that we need to switch URI format to WFN format. This means that pulling CPEs from NIST will be stored in the database in WFN format.
very interesting Feature. However, you have always pointed out that Eramba is not and should not be used as a full asset Management tool. How should this be implemented then? When Managing the vulnerabilities I need to map them to the specific Software / Server or whatever. Thus I would Need to add every single asset to Eramba? Or is it thought to be used in another way?
I think the concept kind of remains (i might be wrong and this things typically get more clear as the feature is built and tested) for example, i dont need to list all my Ubuntu 16.4 systems … they are all ubuntu 16.4 and one vulnerability will still apply to all of them.
This is not fully designed, so is best to wait a little bit.
Grafeas (https://grafeas.io/) is a project backed by google that is aimed at managing the software supply chain. In-toto (https://in-toto.github.io/) is also a relevant project which is closely related to grafeas. I’d personally prefer that eramba be integrated to such a tool rather than trying to duplicate such functionality themselves (e.g. have you consider containers and how vulnerabilities map to such assets).
i guess we are not that off with this features : )
it just seems to me a bit “green” and i’m also stumbled that no international standard tried to normalise how we describe software … CPE was the closest i have seen so far.
The project does seem to have limited uptake outside of google but talks at KubeCon this year suggest that Google is using it internally and has a team of around 8 people working on it.
Kelsey Hightower has also done a demo of using the system alongside kubernetes to manage vulnerabilities of deployed software: https://github.com/kelseyhightower/grafeas-tutorial
Does this mean that Eramba will be able to handle detailed server lists on the Asset side of the house now, or will this continue to not be advisable? I suppose if not advisable, then you could still associate it at a group level - i.e. Application X Database Servers, etc.
Thinking about the workflow for findings that come out of scanners - I think there’s one more resolution that’s missing. When there’s a false positive (i.e. investigated and determined to be not relevant/non issue), this is well covered by the “ignore forever” filter. However, let’s say it’s a vulnerability that needs to be tracked to resolution (suppose it’s a long project) OR be considered an exception that needs to go through the exception management process - that would be something great to be able to track within other modules.