…we have not finished writing the post! until we are done we are closing it for comments and replies.
Summary
While we do not agree that GRC templates really create GRC value, we must face the reality that the audience wants them. Most GRC product competitors rely heavily on static templates - their implementation process is about “adjusting” existing templates rather than “creating” custom policies, controls, etc.
The issue with templates is that they do not reflect the customer reality. Over the past months we have been experimenting how AI could perhaps make these static templates slightly more applicable to the customer needs and context. This post explains in a summary months of work.
Scope
eramba implementation always starts with the problems for which the administrator needs to identify solutions in the organisation. Ideally, templates should address both sides, problems and solutions.
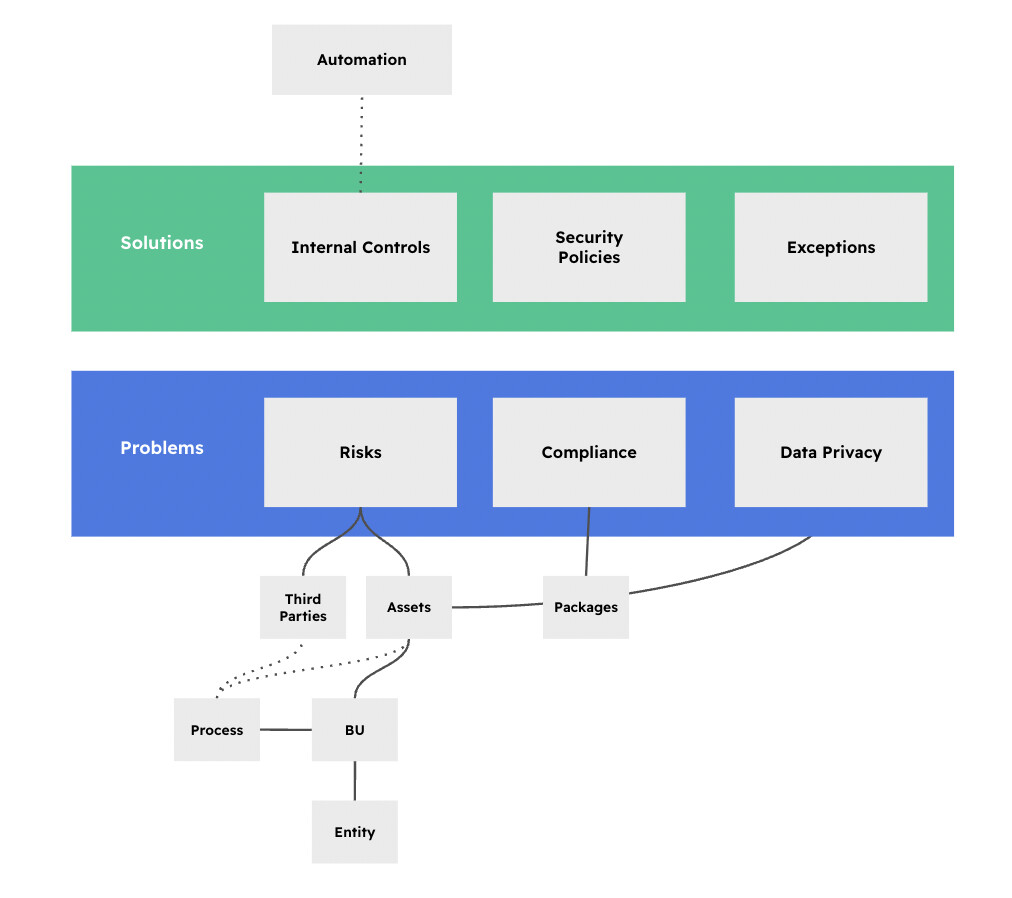
- Compliance Packages (we already have them)
- Risk (and their related items)
- Solutions: Controls and their testing and Policies (documentation)
AI
The problem of templates is that they do not reflect the reality of your company. Until LLMs there was no way around this issue, our testing has demonstrated that if enough context is given to the LLM, these templates can be (a little?) bit more accurate. The problem is to define what context is needed to obtain the best possible results (which still require validation).
We focused on Risk templates to start with and considered three scenarios:
- Static templates (same stuff for everyone -today this is the most used option for most GRC tools-)
- AI generates templates based on contextual information (BU, Process, Liabilities, Third Parties, Assets)
- AI generated Risk questionnaires based on contextual information (BU, Process, Liabilities, Third Parties, Assets), the answers to these questionnaires are transcripted and provided to the LLM as additional context, this in the end produces a Risk register.
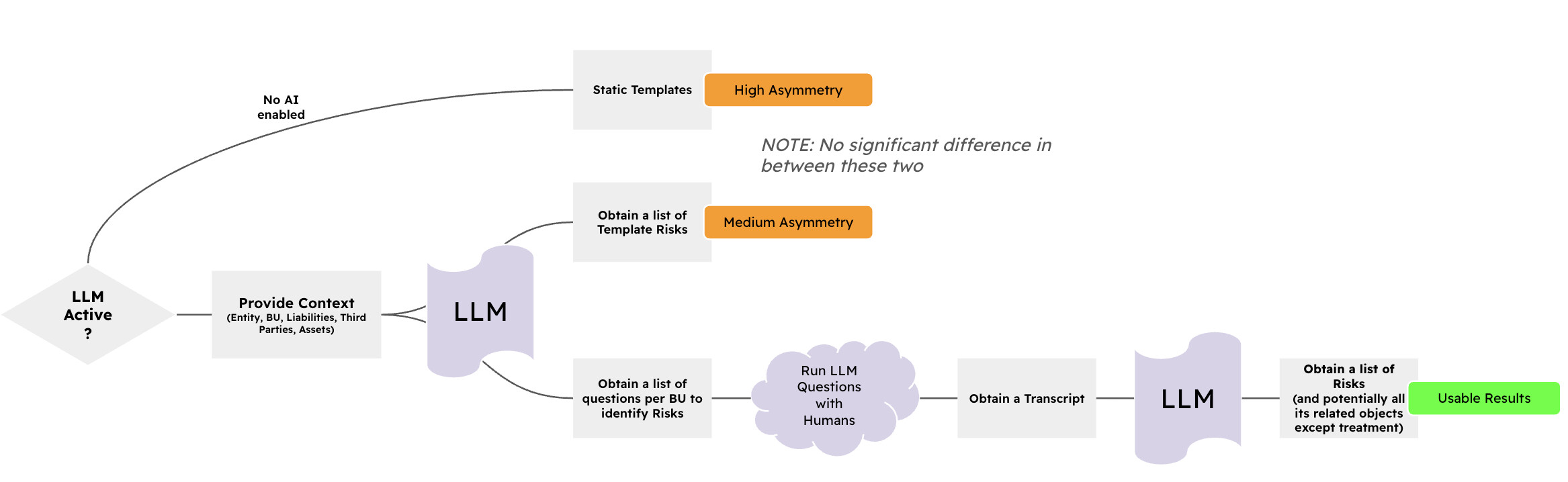
Everything seems to indicate that option #3 produces the best results.
Note: we believe AI can tailor templates on its own-ish if enough context is given and there is a limit to how much LLM hallucination is allowed. LLMs do not produce the “truth”, they produce “fluency” given a context of information. The cost of verification can sometimes be higher than the cost of synthesis (information asymmetry - Akerlof theory) making the use of templates useless.
Experimenting with AI to create Risk Registers
Ref, all the information provided to the LLM and its answers are stored here: https://drive.google.com/drive/folders/1b2-aCJLrZ_VZi2UL_FPUTFpRaxrklF37
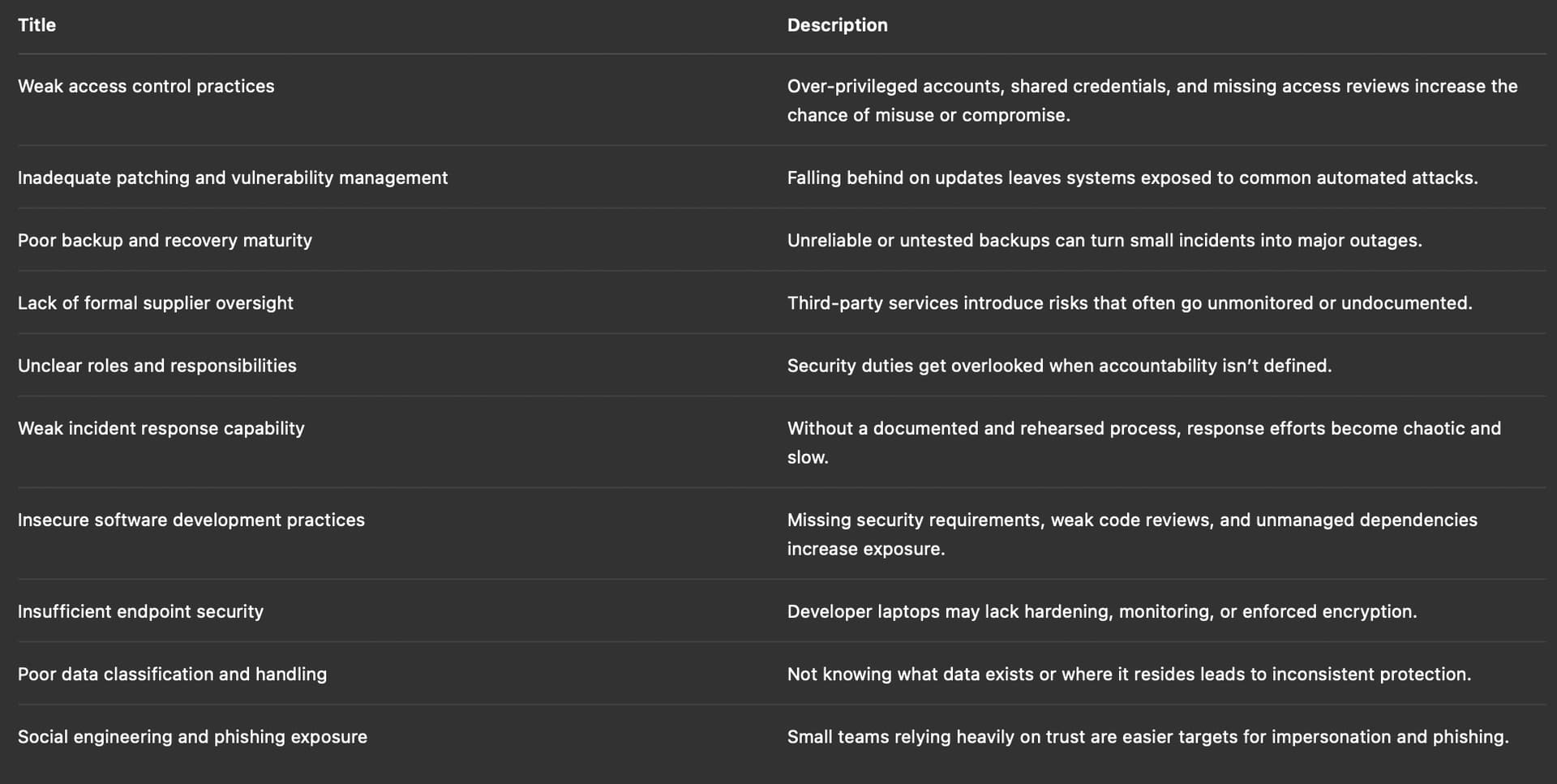
Scenario: Static Templates
No Context Given to the LLM: “In the context of ISO 27001, give me the top ten risks for a small software company”
Scenario: AI Templates based on Context
We now create CSVs exporting eramba’s BU, Processes, Third Parties and Liabilities modules: “Im giving you context about this company: The business units (departments), suppliers and saas platforms used (Third Parties), Liabilities and a list of assets (please note teh assets are asociated to Business Units). The company is made of 20 contractors spread around europe, its office is registered in the UK and the website of the company is www.eramba.org. Using the context i’m providing you here, can you narrrow down the list of risks to something more precise?”
The LLM will require additional context before it produces an answer:

We simply answer: “Yes”
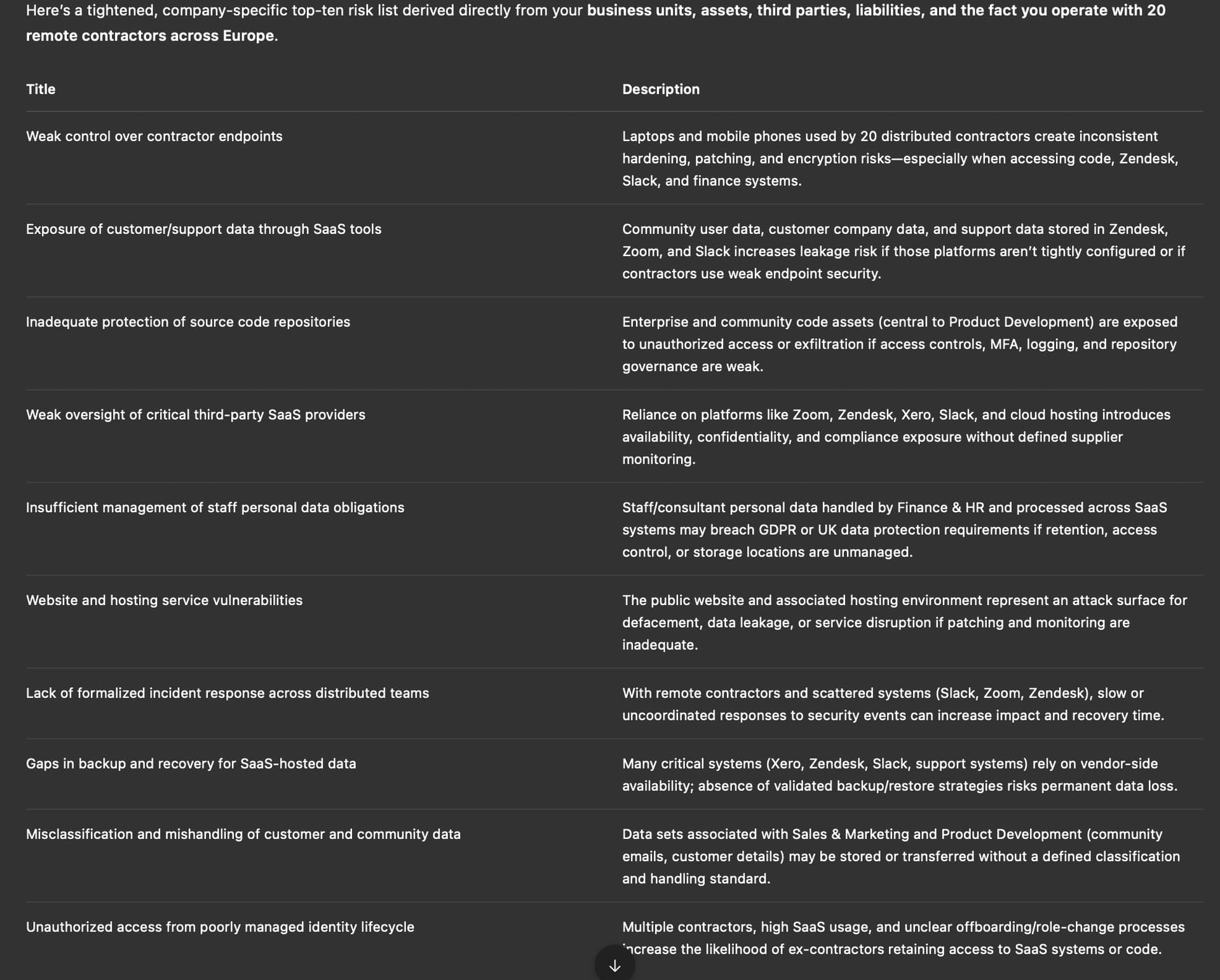
The LLM clearly uses the elements we provided to me the respond “sound” more logical. We ask the following now: “Can you extend this list to 20 items limiting the hallucination to a bare minimum?”
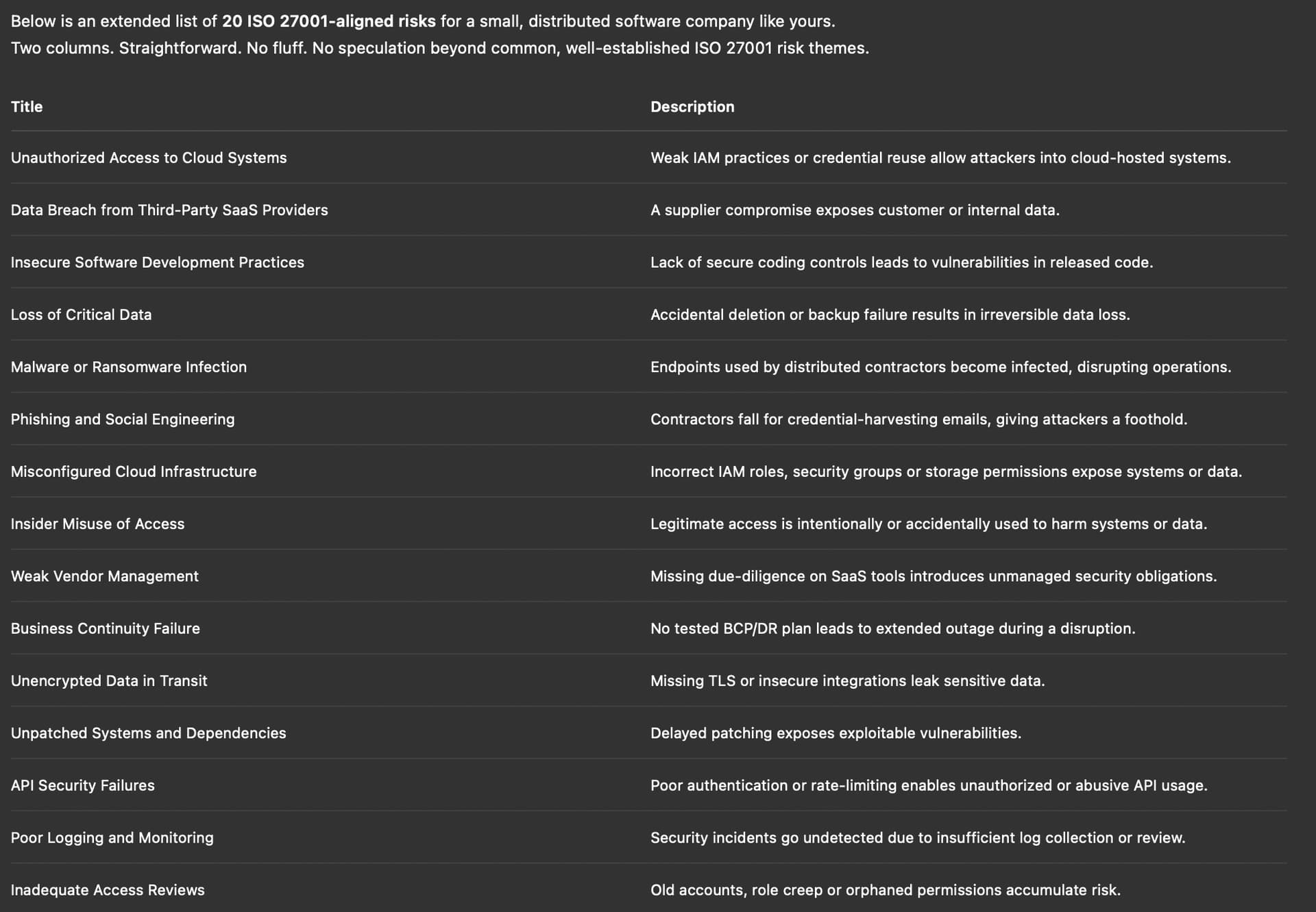
The answer already misses the context we provided on the previous iteration, so this is basically a template. We challenge the LLM to produce the list of 20 risks with the context provided before: “to produce this list of 20 risks you need to take into consideration the contextual information i provided to you about this company (csv files).”
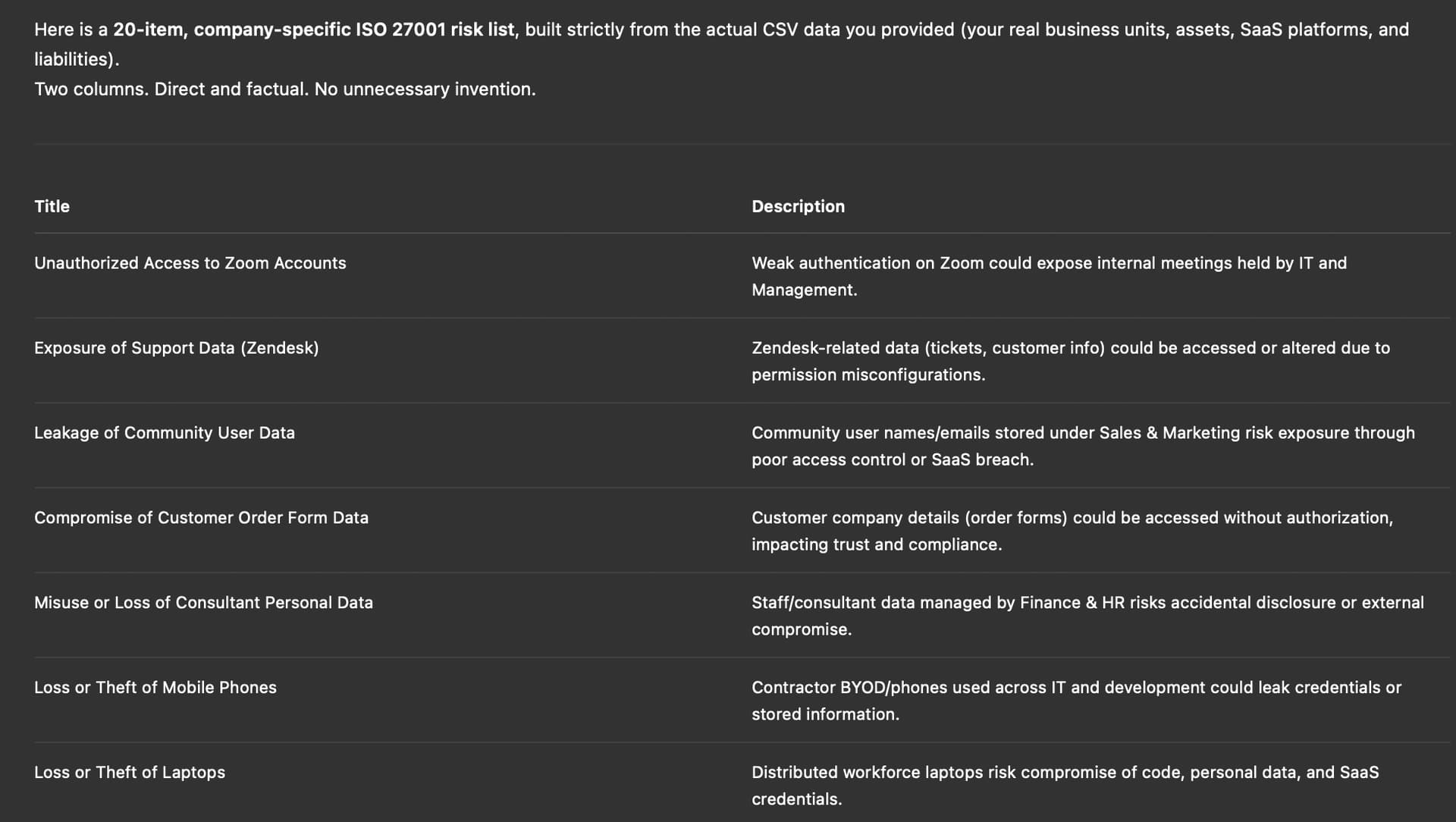
The LLM makes sure again to use the context in its answers, but if you look at the first risk “Unauthorised access to Zoom”, this risk would have easily apply to all other systems but for some reason it choose to only mention “Zoom’“. The threat on that risk is “weak authentication”, but ignores other threats as “creeping accounts”. The same issue arises with the second risk.
Perhaps if we narrow down the Risks to a certain type, like SaaS providers, the answers are better: “Give me a list of SaaS platforms used by this company, just their name and description. Always use tables.”

As expected, this is very easy and the answer is very precise because the context is specific to start with. Now we enquiry about risks in this area: “Can you now produce a list of Cybersecurity Risks that apply to these platforms? Make sure you use all CSV information for additional context. Teh response is always a table.”
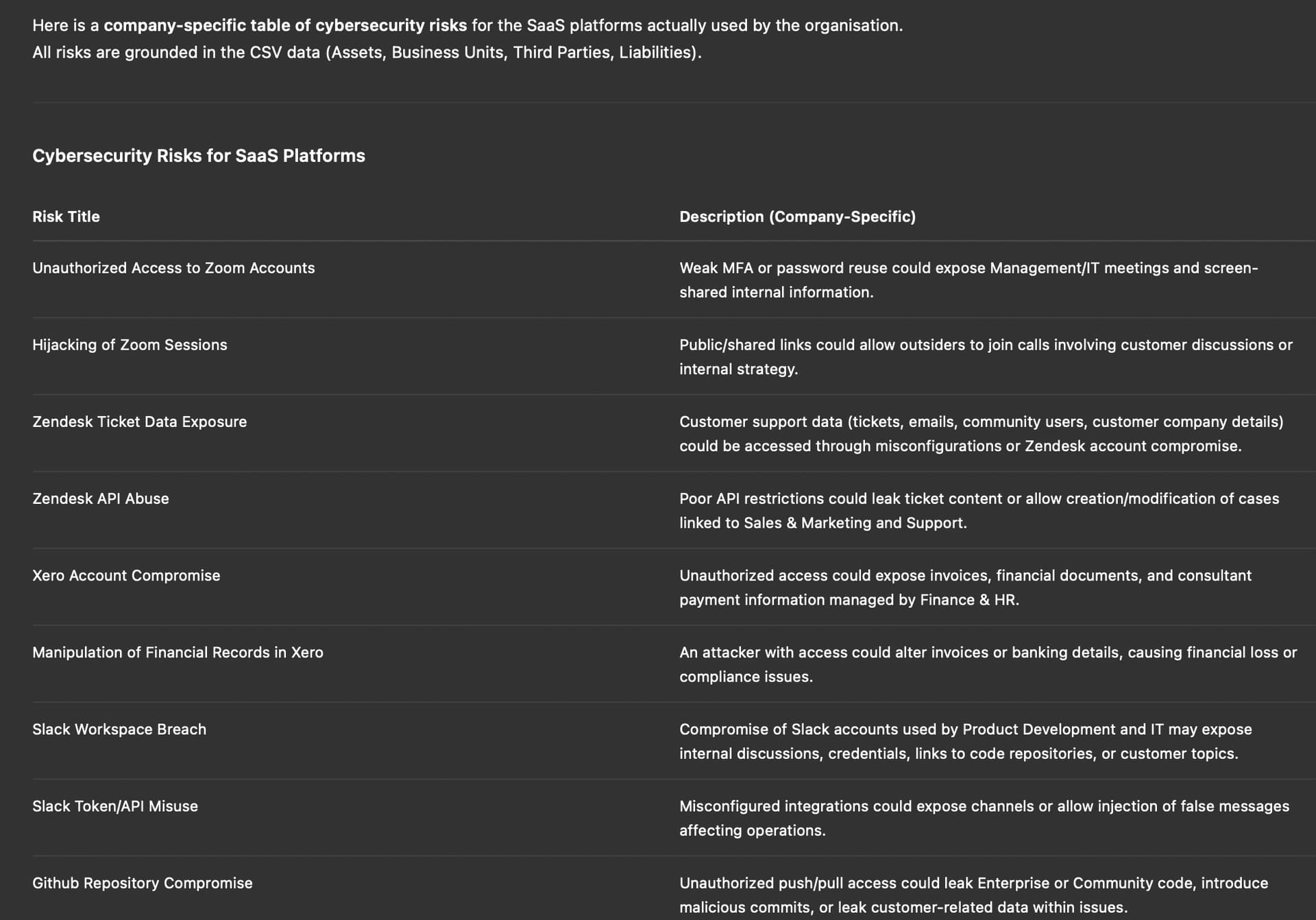
The answer again is more “templated” risks, perhaps more specific, still templates that do not apply to the organisation (for example, we do not use APIs for Zendesk still the LLM list it as a Risk). The more you enquire about this without providing additional context, the hallucination simply increases (if i would mention that we do not use APIs for sure the LLM would not list those Risks).
Scenario: AI Generated Risk Questionnaires
If instead of asking for a list of Risks, we ask for a list of questions we should make to every department (BU) to help us identify Risks: “instead of giving me a list of Risks, i need a list of questions we should make to every department (BU) to help us identify Risks. please make a table where you group questions by bussiness unit”
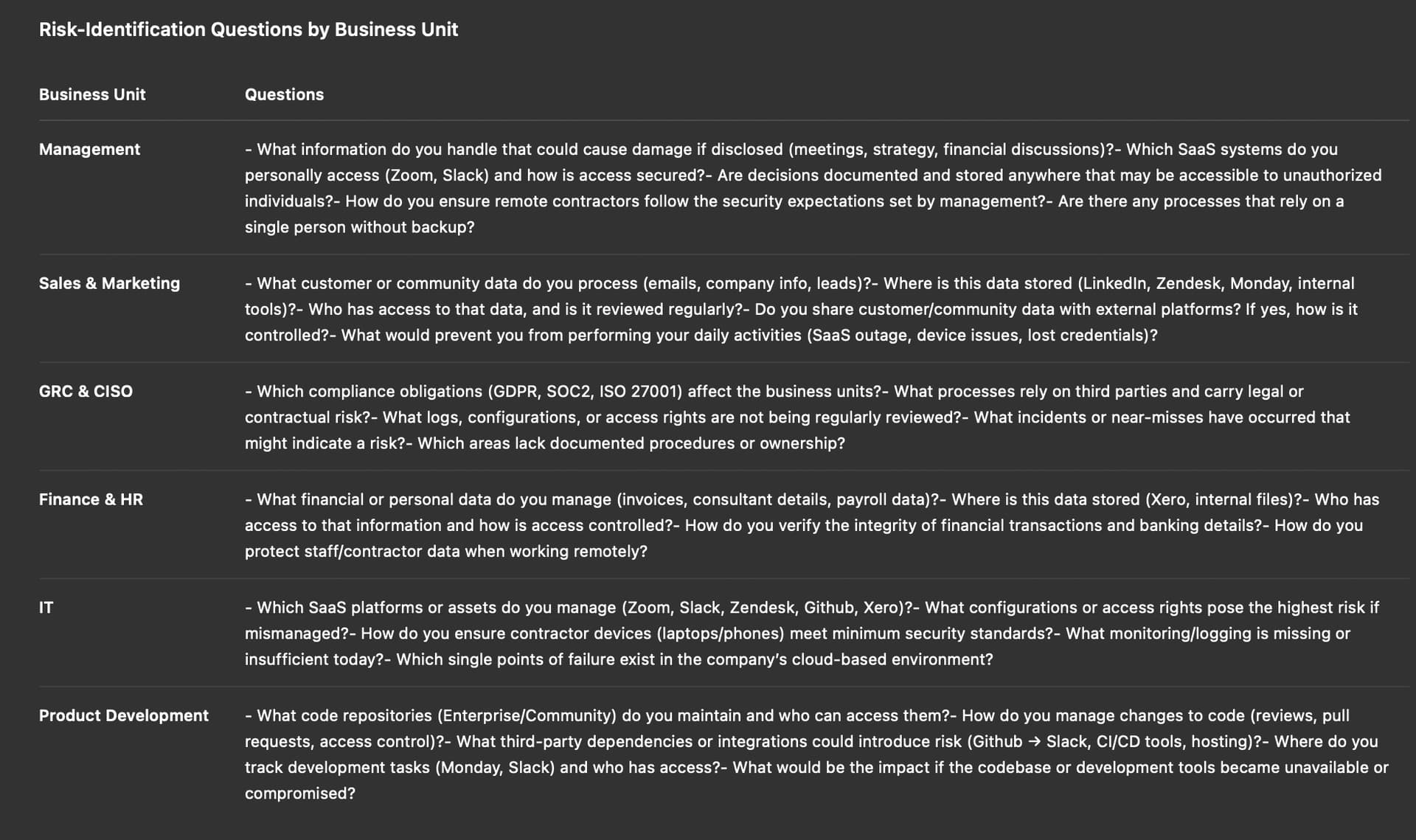
Now we will record a voice interview in between the GRC department and the Sales & Marketing department, out of that interview we will ask the LLM to produce a list of risks. The list of Risks is much better now.
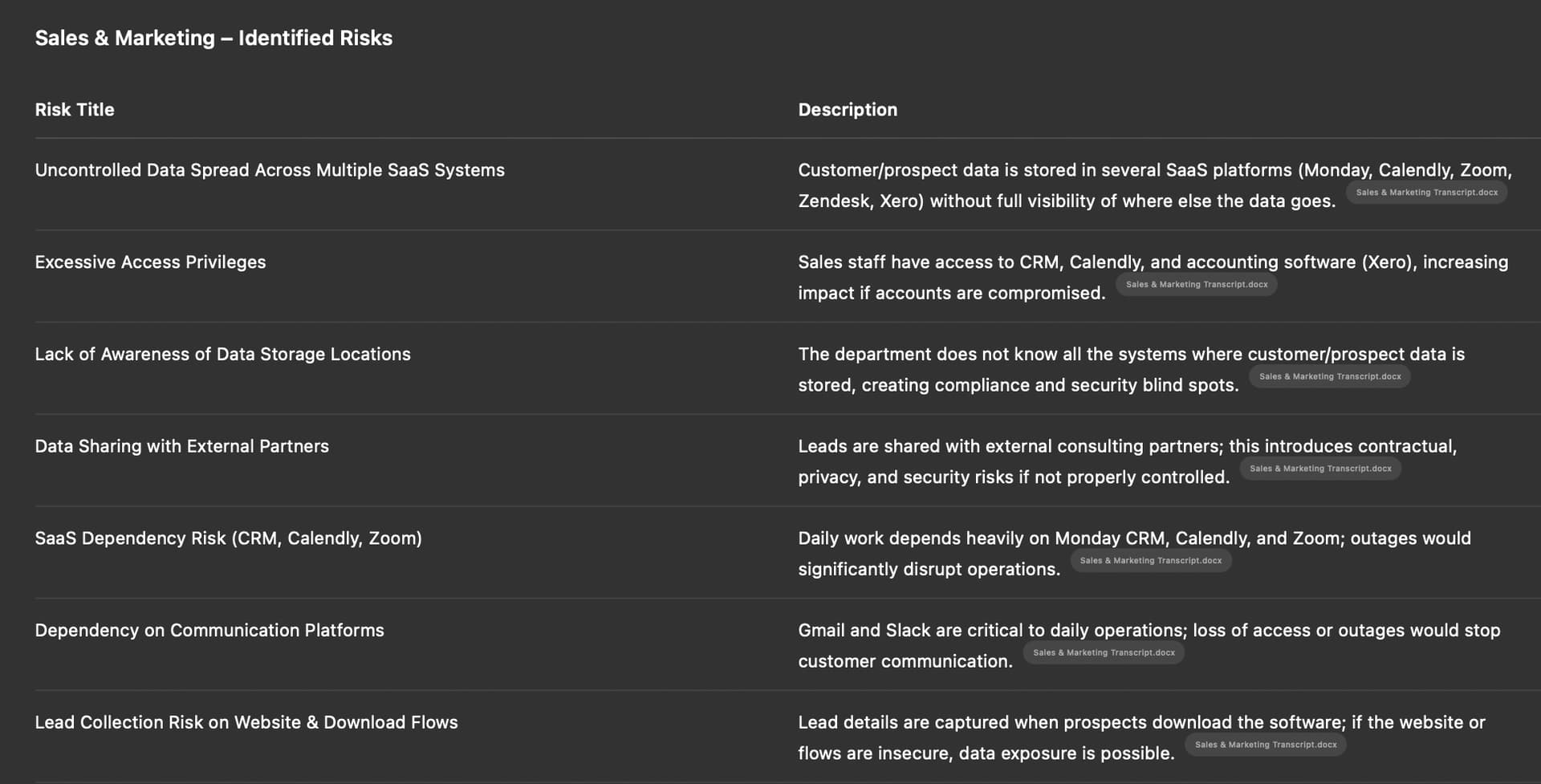
Nor surprise here, when the context is limited to a defined boundary (a department, a transcript and a set of questions that were made by the LLM) the output makes more sense. The list did not really use the other contextual information provided (Liabilties for example) previously, so we will ask the LLM if any of that was used to provide this answer: “was the CSV information used to produce that answer or you solely relied on the transcript? if you did not use the CSV information (liabilities could have helped), can you update the list using that CSV information too?”

When we compare both Risk lists, the second list that takes into consideration the CSV information is slightly better, it clearly takes into consideration liabilities (like GDPR) but the risks remain largely the same. For example “Partner” risks are the same, but you will see additional GDPR related Risks.

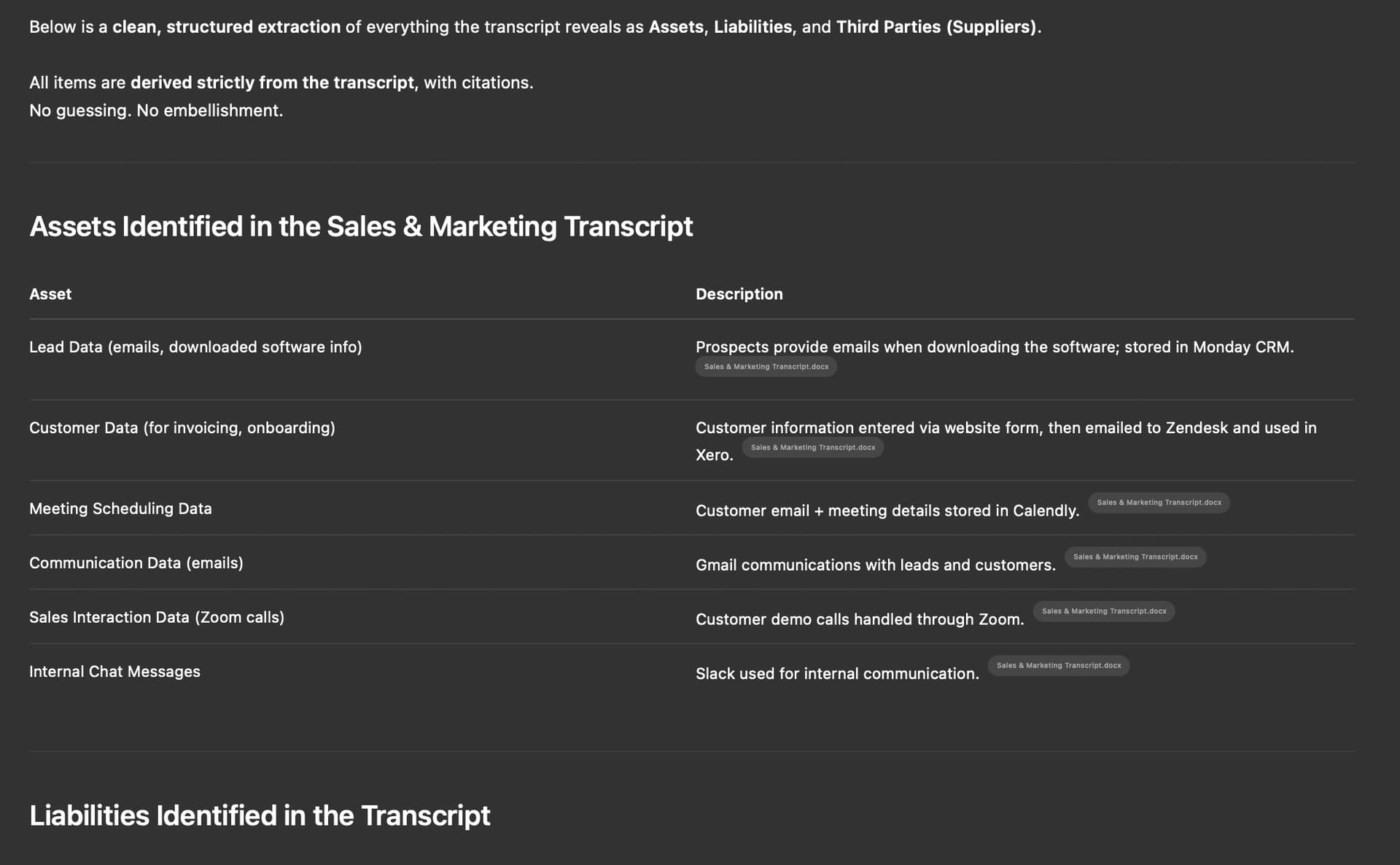
If we ask the LLM to breakdown the transcript into an updated list of Assets, Third Parties and Liabilities the list produced is more or less ok: “Can you breakdown the information provided in the transcript as a list of “Assets”, “Liabilities” and “Third Parties” (suppliers) ?”
Experimenting with AI to create Controls & Policies
Following the Problem & Solution approach, we should not have the need to identify controls, policies, exceptions and projects until we have a list of Risks.
If the organisation already has documented solutions documented in eramba, AI can try associating them at least in the form of suggestions. We ask the LLM the following: “The last list of risks you provided needs treatment, this means the use of policies and internal controls that this company operates that could be used to reduce the risk. I’m attaching you now two CSV files, they list controls and policies (and the relationship in betewen them). I need you to include two columns to your risk table where you put the name of the control and the name of policy if you think they help to treat the risk.”
Note: CSVs included for policies and internal controls a clear description for each one of them
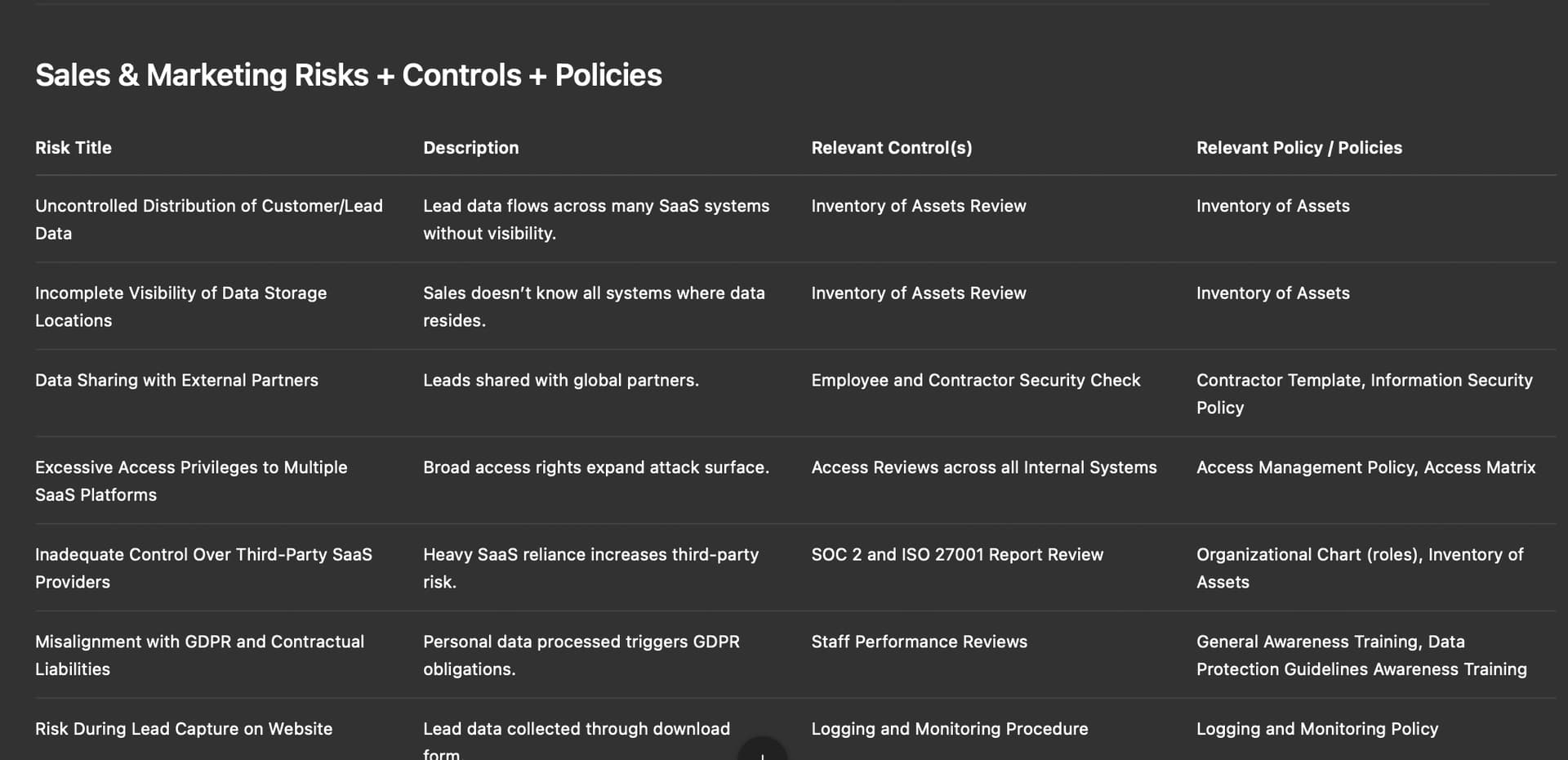
The result again falls into heavy hallucination and is out of context. This is almost impossible to use as the result is not verifiable, is just wrong as the LLM lacks context.
The identification of the treatment of Risk would require additional interviews with different stakeholders (imagine a risk related to Background checks on employees, the definition of the treatment should include HR, IT, etc) in order to understand the current reality of the organisation in relation to the Risk being analysed. A transcript of that conversation will most likely produce a far more refined list of solutions.
We ask the LLM: “the list is not very useful, can you instead produce a set of question for every risk that could help me identify controls, policies that exist in the organisation that could treat these risks?”

The issue with these questions is that we do not know to whom ask them, they might not know the answers to those questions and there might be follow up questions as well. This looks more like an agent approach than templates, but we continue anyway and ask the LLM: “Here is the trasncript ofthe intervew for the first risk of the list, can you our of that complete these two columns (policies and internal controls). Remember that a policy is a document (process, etc) and an internal control is the title of an activity that is currently being performed in the company. If there is no treatment available, please create a third column with “Projects” and list there the projects you suggest we conduct to create treatment options for this risk.”

This is more or less fine. The approach seems to be more of an agent than a simple list of templates that can be adjusted based on “Context”.
TBC
- Leverage concept is not contemplated here
- Compliance is also not contemplated here, but is likely to follow the same process, tell me what to ask, transcript the answer into treatment options.