Scenario:
Your company is getting started in the world of GRC and you would like to work on Risk Management. You are not clear on what type of Risk Classification, Calculation, Matrix you should use.
Question:
What is a simple way to get all this started?
Answer:
Risk classifications, calculations and thresholds (these matrix with many colours) are basically a way for Risk practitioners to discern from a large list of risks, which ones need more attention as they could produce more damage to the organisation.
The thing is that putting a “weight” to a Risk is not easy because the “scales” (analogy of course) we have in our industry (Cyber) do not measure in Kg, Pounds, Etc (numbers) but instead on attributes, such as “High Damage”, “Low Likelihood”, Etc.
$300 bucks an hour consultants will bore you to death talking about “Quantitative” (Kg, Pounds, Etc) and “Qualitative” (attributes in our example) theories and use cases (which don’t work in real life). We prefer to keep it simpe which is what most organisations can handle.
The reason is simple, the industry (Cyber) has no clue what the likelihood of our website being hacked is. Is it 1 in 1m visits? 1 in 500 days? If our company goes public, does that change? To what numbers? What is the competition likelihood? How is our website built? How is theirs built? … endless questions (because we have no data).
In the insurance business we know with precision what is the likelihood of a frontal crash in London SW1 on a weekday with rain. Because we have numbers and historical records. Simple.
The impact of things has the same issue. Impact is easy to determine when the cause - effect is connected (or very close) and obvious. For example:
If i’m a consulting developer making $600 bucks a day and my laptop goes on fire in the morning then obviously that day I wont be able to work and therefore i wont be able to invoice it. $600 impact, easy peasy.
When cause - effect are distant, is nearly impossible to tell the impact of anything.
If i have a team of salesman around the country meeting customers offering our services and products, if the website gets hacked and defaced with a meme of Gaddafi on it, will that kill the sales of all these people? Permanently? or those that they met that day? Are they even using the website? How would anyone estimate the loss? Impossible unless you ask a charlatan.
Then comes the math, the one used to determine the “weight”. Shall it be a multiplication or an addition of factors? if the asset is considered in the equation or not, if it is considered if it should include the confidentiality, etc. We hear many stories about this.
It takes high-school math to know that if you have subjective data in the variables of (simplistic) equation, the outcome of that equation will be subjective. Don’t get me started with the math please … any model you see on Risk spreadsheets is overly simplistic in the eyes of a basic Statistics university course where probability is read.
So the easiest way to get started is to keep it simple, we recommend you the following: Likelihood x Impact, where:
Likelihood will be split into three options which are very easy to define:
-
Low (Value=1): it never happened before and no-one believes it could happen
-
Medium (Value=2): it happened before, but it was once in a million, it won’t happen again
-
High (Value=3): it happened before and could happen again
You use the “historical” data to answer the classification, the rest (the future part of the sentence) is subjective.
The impact:
-
Low (Value=1): our CFO believes the impact won’t affect their year end results
-
Medium (Value=2): our CFO is not sure and thinks there is a possibility that year end results could be affected
-
High (Value=3): our CFO is almost sure year end results will be affected
You ask the numbers person to give you their IMPACT (financial if you work on a for-profit organisation) view on EVERY risk. You can not ask the “affected” business manager because they see their business alone, not the overall business (as the CFO has to). This will limit the subjectivity and will let a knowledgeable person do the estimate (instead of you, on the GRC department making calls).
The risk ranking will be nearly the same for all risks, from 1 to 9 (since you are multiplying factors).
The numbers won’t tell as much as the classification (because as we explained before, you can not calculate numbers with meaning). As for a matrix, you can call these ranges anything you want, for example as shown on the matrix below.
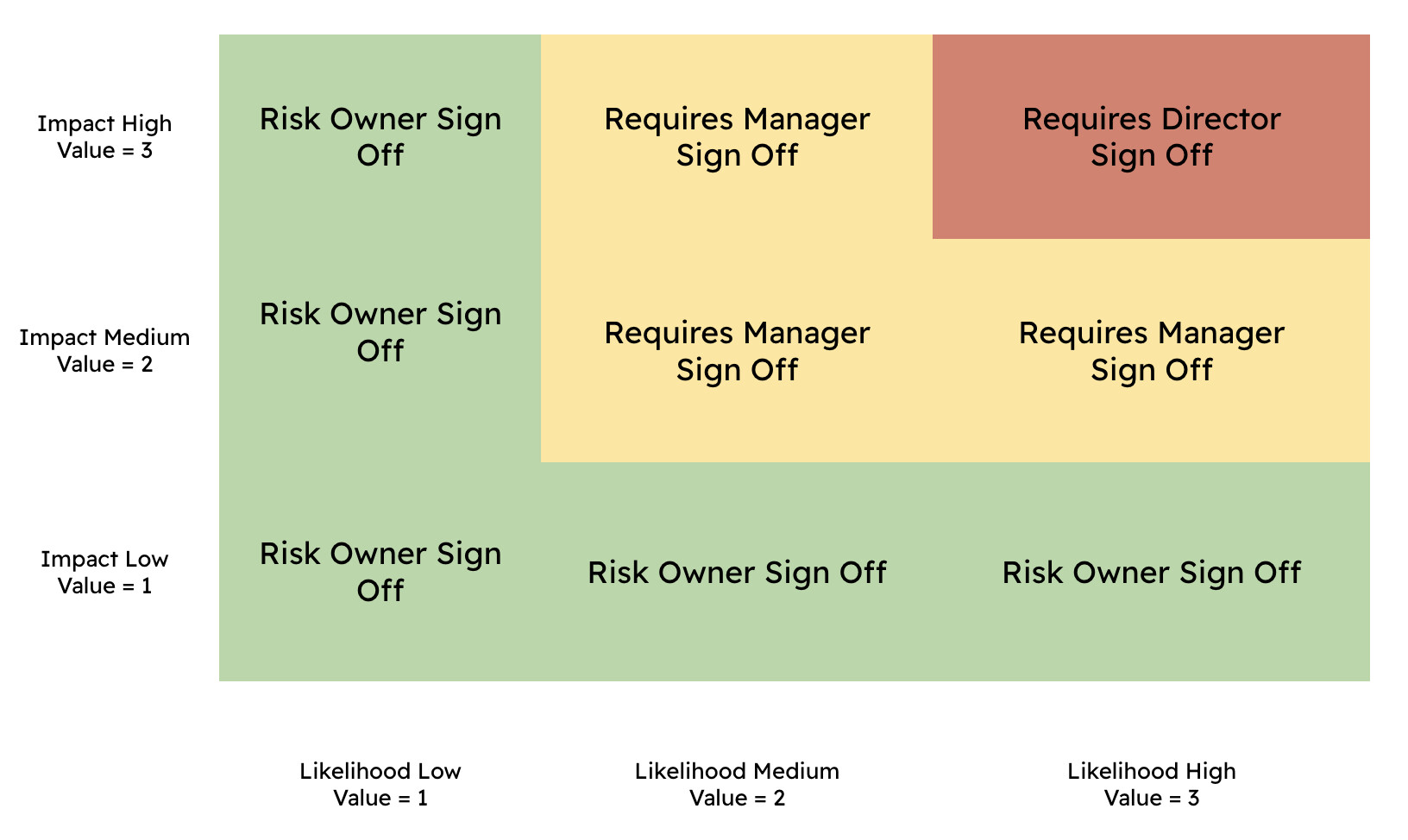
As you see we use the classifications to decide who must decide what to do with a Risk.
Keeping things simple must not mean to keep them unrealistic or without value. The proposed framework has logic, involves professional judgment and uses statistical data where available.