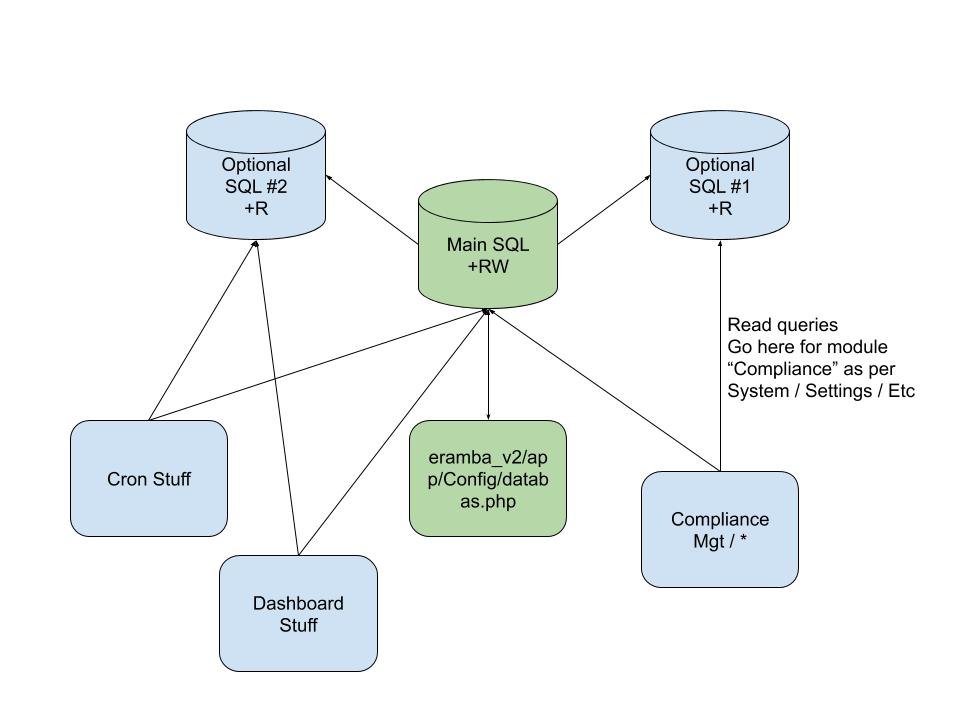
After the cake migration project we’ll work on something we had pending for a long time which is to have a proper scheduler. eramba runs a “cron” every hour, day and year which churn data and update charts, statuses, send emails, etc.
We’ll move all of that to a scheduler with a FIFO style of queue which will be processed every minute (instead of three crontab entries there will be one). As we do this, we will also “decouple” eramba so you choose on System / Settings for each module (internal controls, risks, compliance, dashboards, scheduler, etc) which:
write database to use
read database to use
This will allow eramba to read from multiple +R slave databases and writing in (for a start) on only one. Things like dashboard calculation, status calculation, pdf processing, etc are a b…ch and take a ton of DB I/O and therefore we are pretty confident this will let you scale your deployment pretty easily.
There is no GIT for this yet as we first need to complete the endless and super expensive cake migration, but chances are that just after we finish this project we’ll start with decoupling and the first one to decouple as stated before will be the crontabs into a “Scheduler” module.
Will you be implementing support for a caching layer such as memcached or redis? I suspect that would provide better scalability than having read replicas for the database. From my observations latency is the main issue in speed and so having a remote database such as AWS RDS with a memcache server local to the php app server would give greater scalability than read replicas IMO.
before querying the database, cakephp uses a cache (this is why first load will always be slower than subsequent), that cache which is under eramba_v2/app/tmp/cache/* doesn’t have to be a filesystem (as it is now, files over fs) but can also be redis (cake doc). we never tested this but as things stand now, i dont expect much difference to be honest than filesystem because the cache never grows beyond 100mg, that is what we cache is not all (we many times need fresh data).
note: we can and we do control what is cached and what is not. should we perhaps cache more?
the problem we are trying to address here is not “speed” but “scalability” … what we mean by that (sorry our english is not good sometimes so i need to clarify) is that when data volumes get beyond certain point the system doesn’t not work. we saw that with dashboards on a database which had more than 10k risks.
redis or some server-client cache method will be needed, because when you have more than one eramba running in a different server they will all build their own cache (on the fs) and that will create a mess … they all need to source from a single cache server. could we store data used in eramba (mysql) for routine things such as “Cron” , “compliance” , “dashboard” on a redis? probably but we would need to sync mysql to a redis format and then cake wont read that redis data because is not one of the “datasources” … pewh why didnt i become a doctor like my mum advised me?
cake needs to query sql to work (as we need the latest data which is not cached) so we need something fast that speaks that language. we are interested in external know how to make sure we do the right thing here , we know well by know that there is a ton of experience out there that can be of use.